back
Toronto, ON
Figma

github copilot
usertesting.com
N → 1
Enterprise SOFTWARE
data management
Sales tools
year
2023—2024
TEAM
2 Product Designers
Product Manager
Tech Lead + Eng Team
Content & Research Team
Confidential information and sensitive intellectual property has been omitted or obfuscated. All content reflects my own work and processes and not necessarily the views of Dell Technologies.
WHAT WAS SHIPPED
In 2023, Dell's Business Intelligence and Data Governance organizations were managing millions of customer records across a patchwork of legacy systems, acquisition databases, and regional tools, 13 different platforms for 13 overlapping jobs. The result was duplicated, inaccurate, and increasingly unreliable data feeding sales tools that depended on it being right.
I led design on a new platform, Castle Stewardship, built from scratch in a team of three Product Designer, a Product Manager, and a wide stakeholder group spanning data architects, governance leads, and business intelligence program managers.

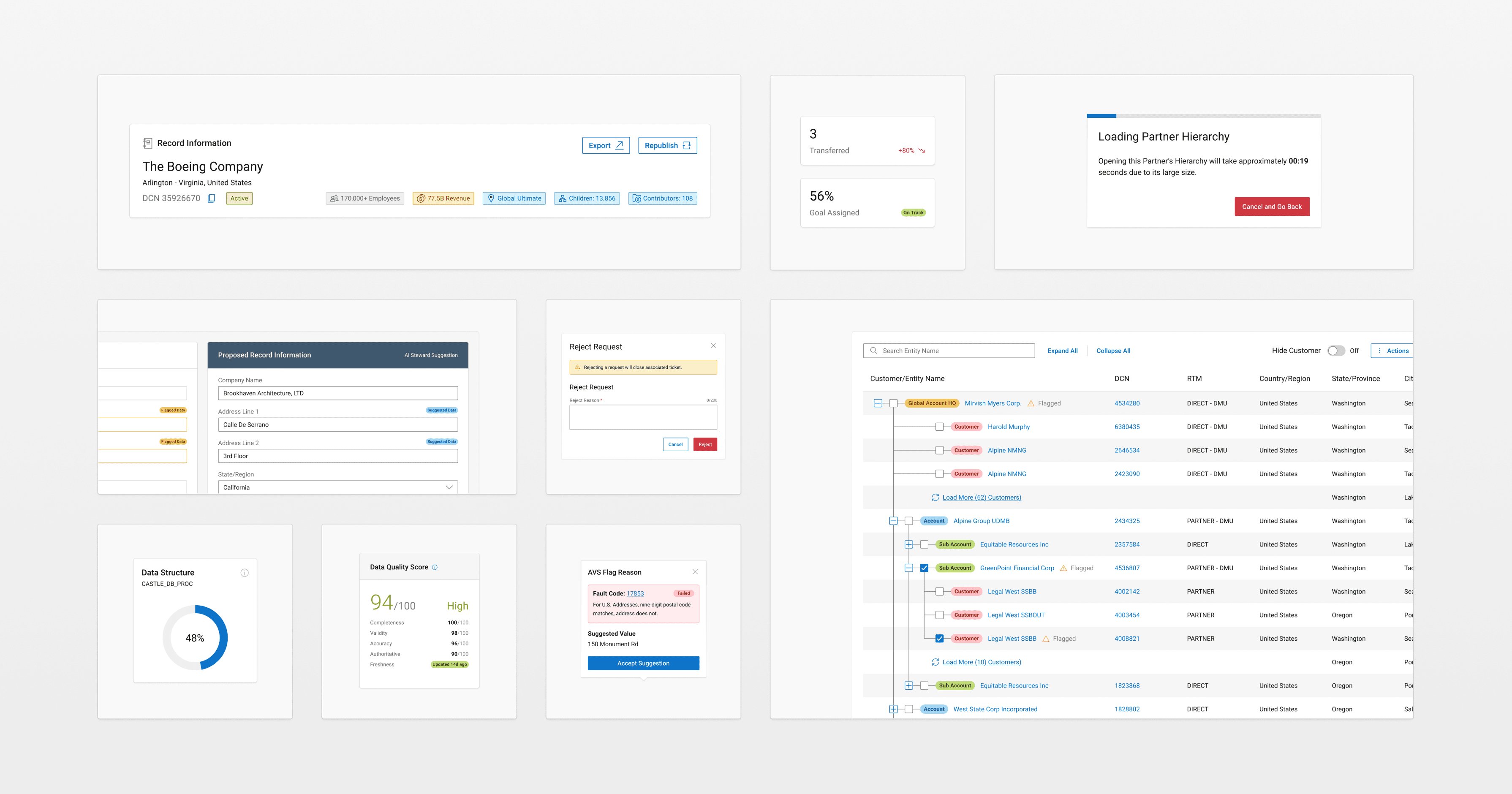

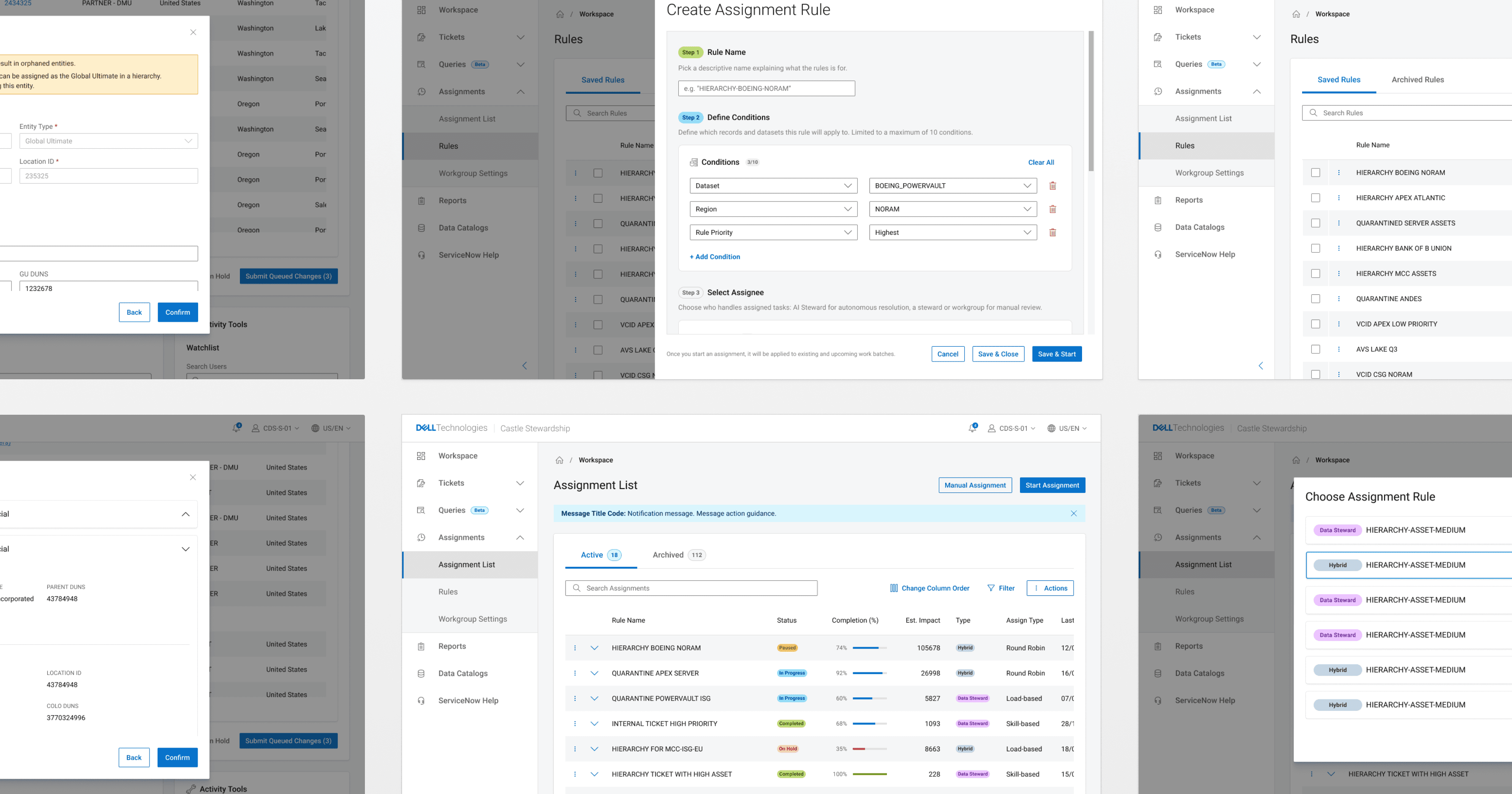
Defining the PRoblem
Dell's data governance teams had a problem that didn't emerge overnight.
Years of acquisitions, platform pivots, and half-finished cleanup efforts left a bloated customer database ecosystem where a single record might carry 20+ individual identifiers, many redundant, most incompatible across systems.
Each database had its own metadata standards. Each region had its own tools.
Enforcing any kind of consistent data quality standard across all of it had become genuinely unsustainable, a governance nightmare quite frankly.

To solve for this scenario, the Business Intelligence org had a plan: converge records from other databases into a unified golden record database (aka Castle DB) the one source of truth for customer data across the company.
What they needed was a tool that would let data stewards actually do that work: clean records, resolve issues, make governance decisions, and do it without switching between platforms all day. With that premise the design work started.

Process & APPROCH
The first real strategic decision came after sensing that the governance was dangerously leaning into bringing all functionalities across all tools as MVP priority requirements for Castle.
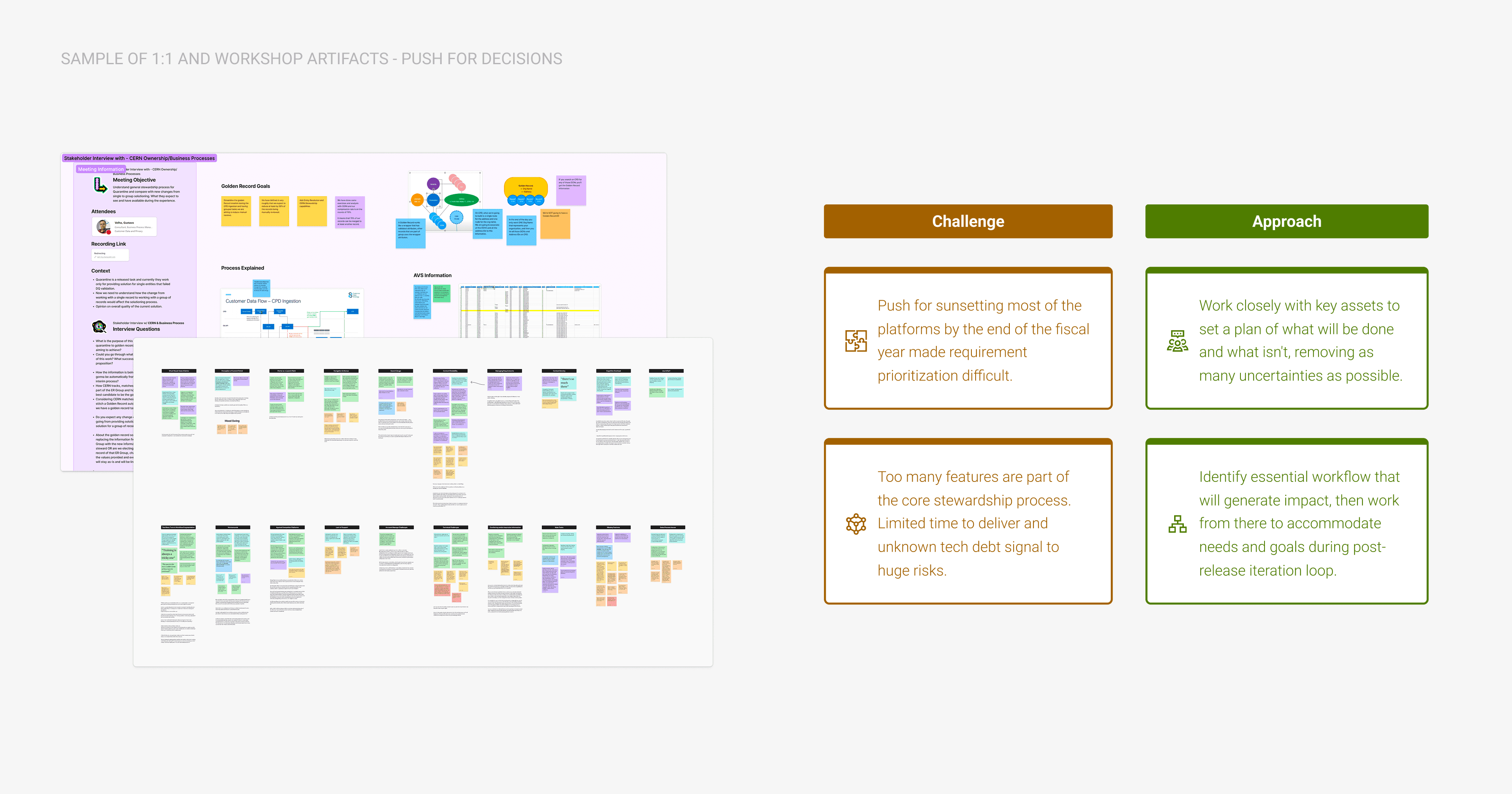
The 13 existing platforms were complex, siloed, and designed at different times for different purposes. Trying to recreate all their features in one place would have taken years and produced something just as bloated. Instead, the work was scoped and developed based on a question that was asked repeatedly like a mantra: “what does a steward actually need to do their job?”.
A few workshops and meetings were required with data governance and BI key decision-makers to settle into a path that shaped everything that followed: Keep the absolute essential, strip everything else away.

That question was answered after gathering opinions from each designated Steward Lead and key stakeholders during weeks of 1:1 and team discussions.
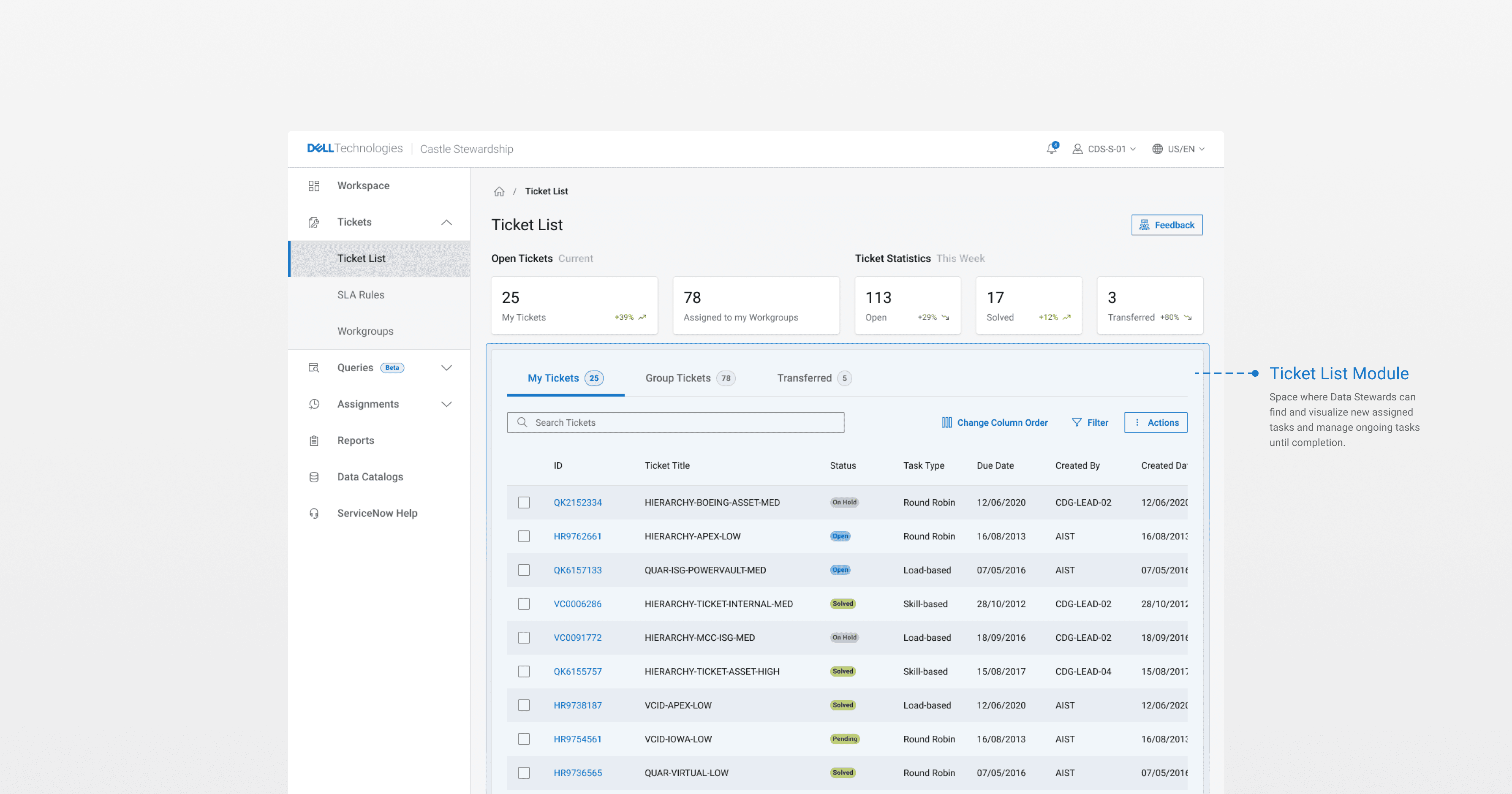
The process for data clean up was already thought out: Records failing the data quality API would land in quarantine and auto-generate a stewardship ticket. Stewards would pick up assigned tickets, work through structured tasks, and commit decisions, sending resolved records back through the quality check before promotion to Castle DB. If a record failed again, it looped back with full issue history attached.
It was very evident that the research process favours a ticketing workflow. A ticket-and-task model mapped to how they worked, unified the most critical processes from the old ecosystem, and gave us a scalable foundation to build on.
It wasn't the only model considered though: A record-keeper interface and an editable archive both had advocates in the room. But the ticketing model won on alignment as it matched existing mental models, created accountability, and gave us a clear MVP scope.
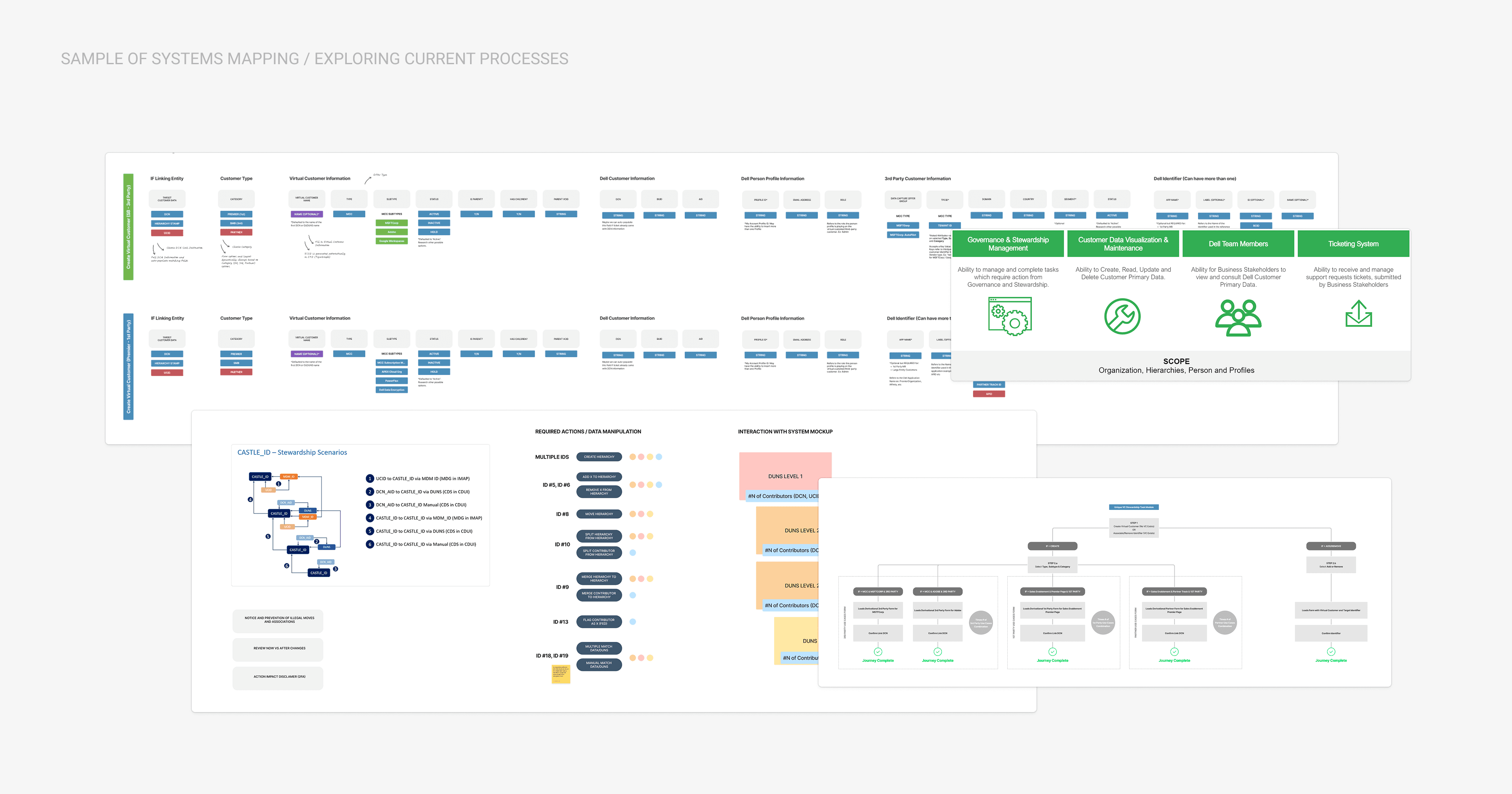
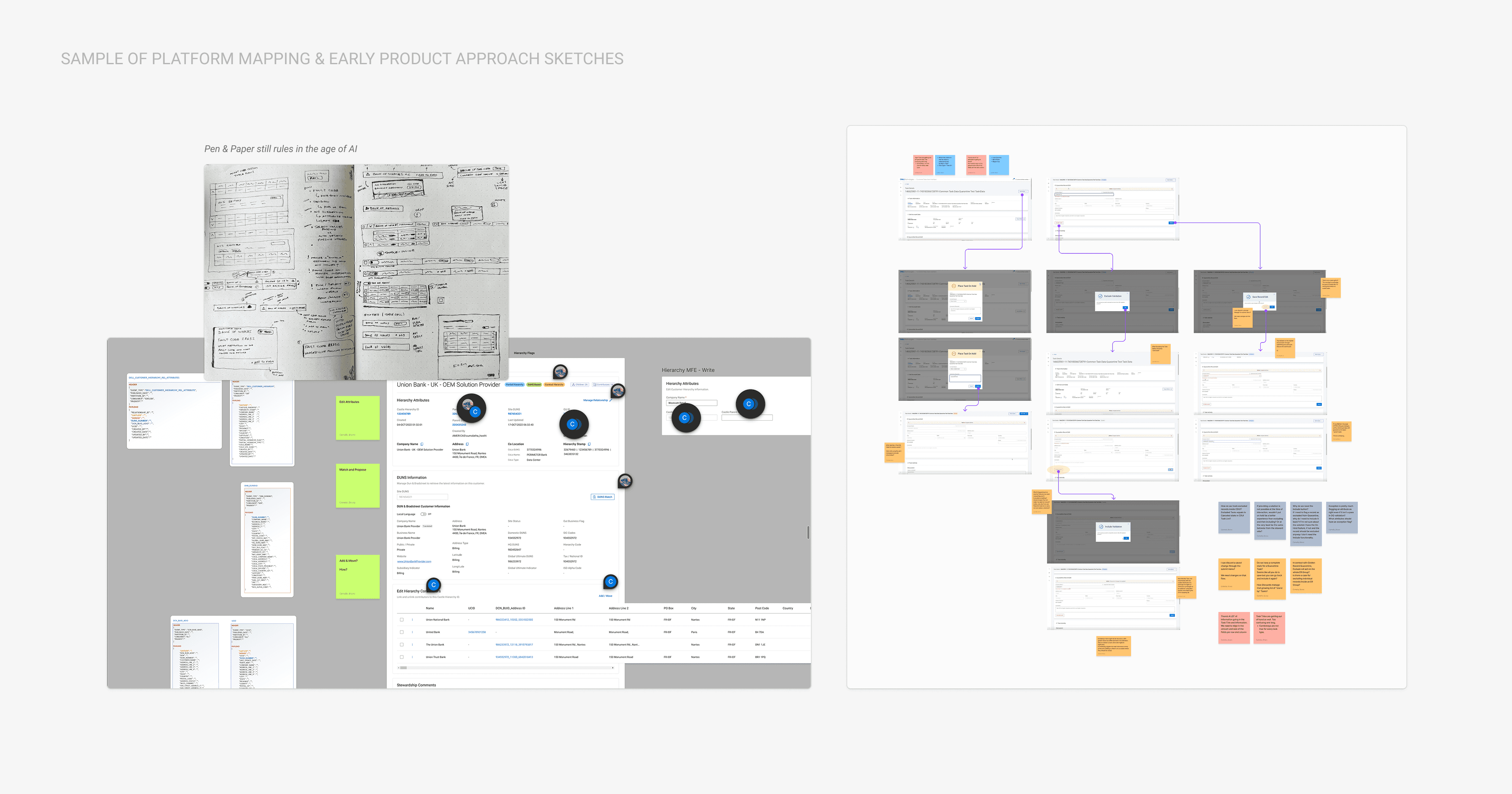
CHALLENGES
I won't understate how difficult the subject matter was. Data stewardship at this scale isn't something you absorb in a few stakeholder interviews. I was shadowing system architects, the BI project lead, and governance managers almost daily, not as a formality… but because the decisions we were making required our understanding of the subject and their domain knowledge at every turn.

The stakeholder landscape was the other challenge. Both the BI and Data Governance organizations had 100–200 headcount each. Every scoping decision touched someone's workflow. Getting alignment on which tasks to prioritize for MVP meant workshopping requirements with multiple steward leads and managers, most of whom had strong and divergent opinions about what their teams needed.
The original plan called for 8 task types at launch. We settled with shipping 4 so we could have time to work on contextual features like Golden Customer Record search and light automation from day 1.
That wasn't a failure, it later proved to be the right call. The timeline pressure was real (other large company-wide initiatives were waiting on Castle DB to be production-ready), and 4 well-designed tasks that stewards actually trusted was more valuable than 8 rushed ones without other features that gave context and speed. We had enough to validate the core model and start building data quality momentum toward BI goals.
Design Decisions
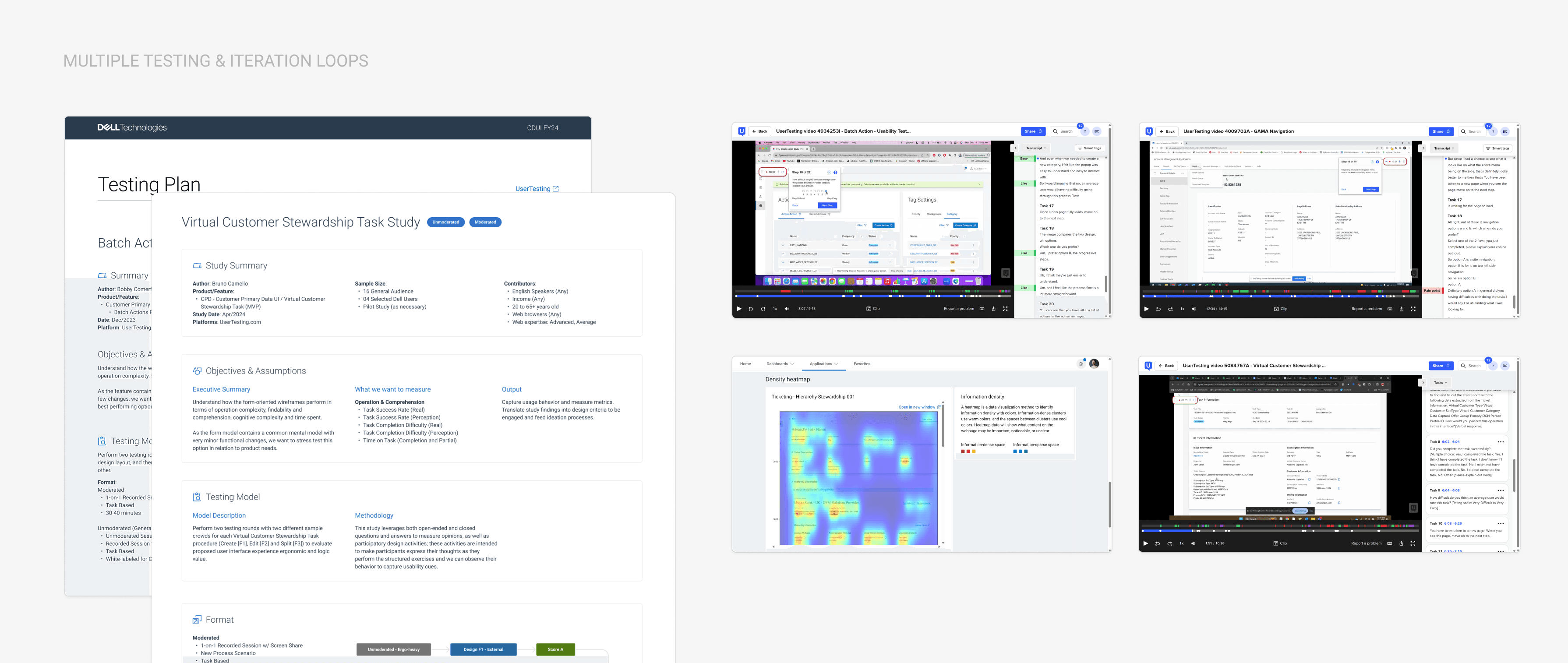
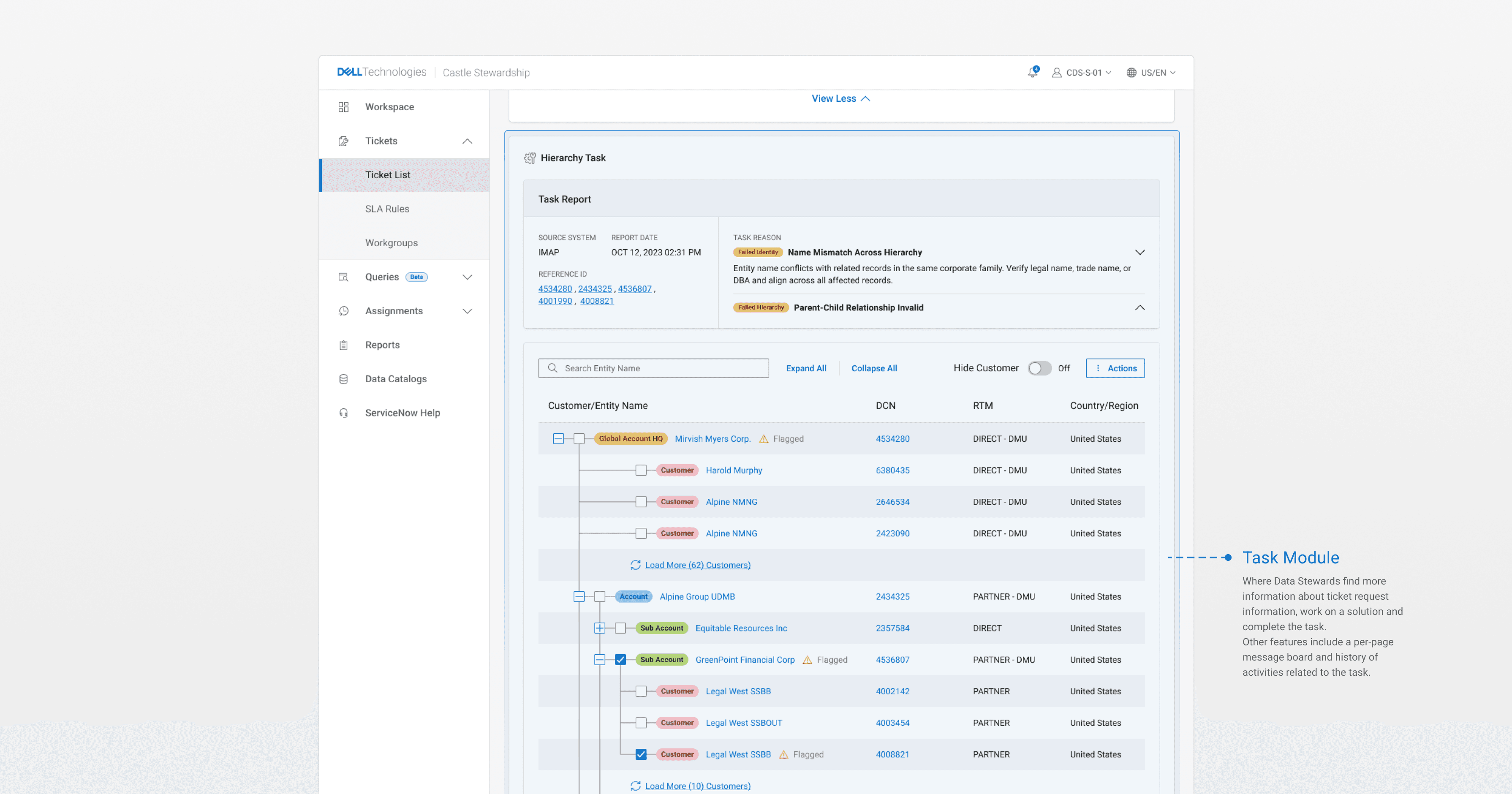
The most technically challenging feature was the task structure itself. Each of the task types had unique data requirements, different decision trees, and slightly different research workflows, but they also shared significant common ground in how stewards approached them.
After several failed iterations trying to design each task type independently, the testing feedback that gave the insight that unlocked progress was that the tasks had transferable structure. They all involved: reviewing flagged data point through surfacing customer data, researching external sources to validate or correct them, and committing to a decision.

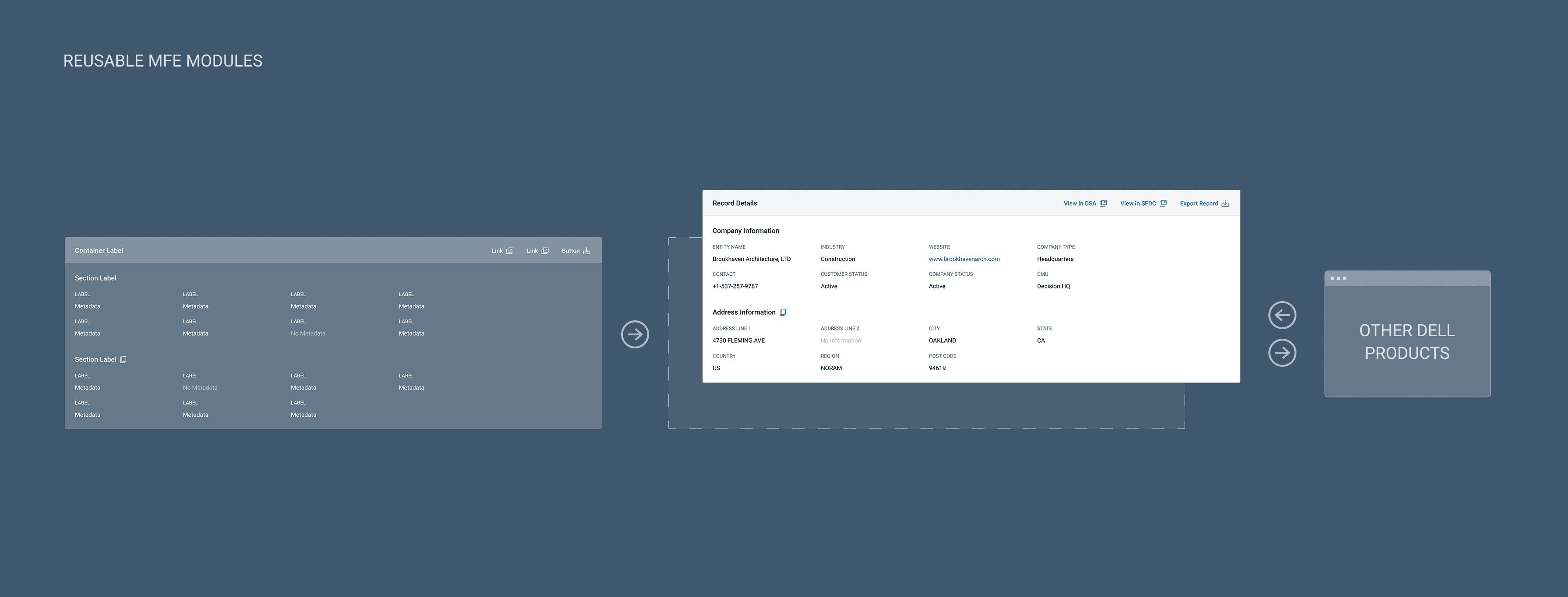
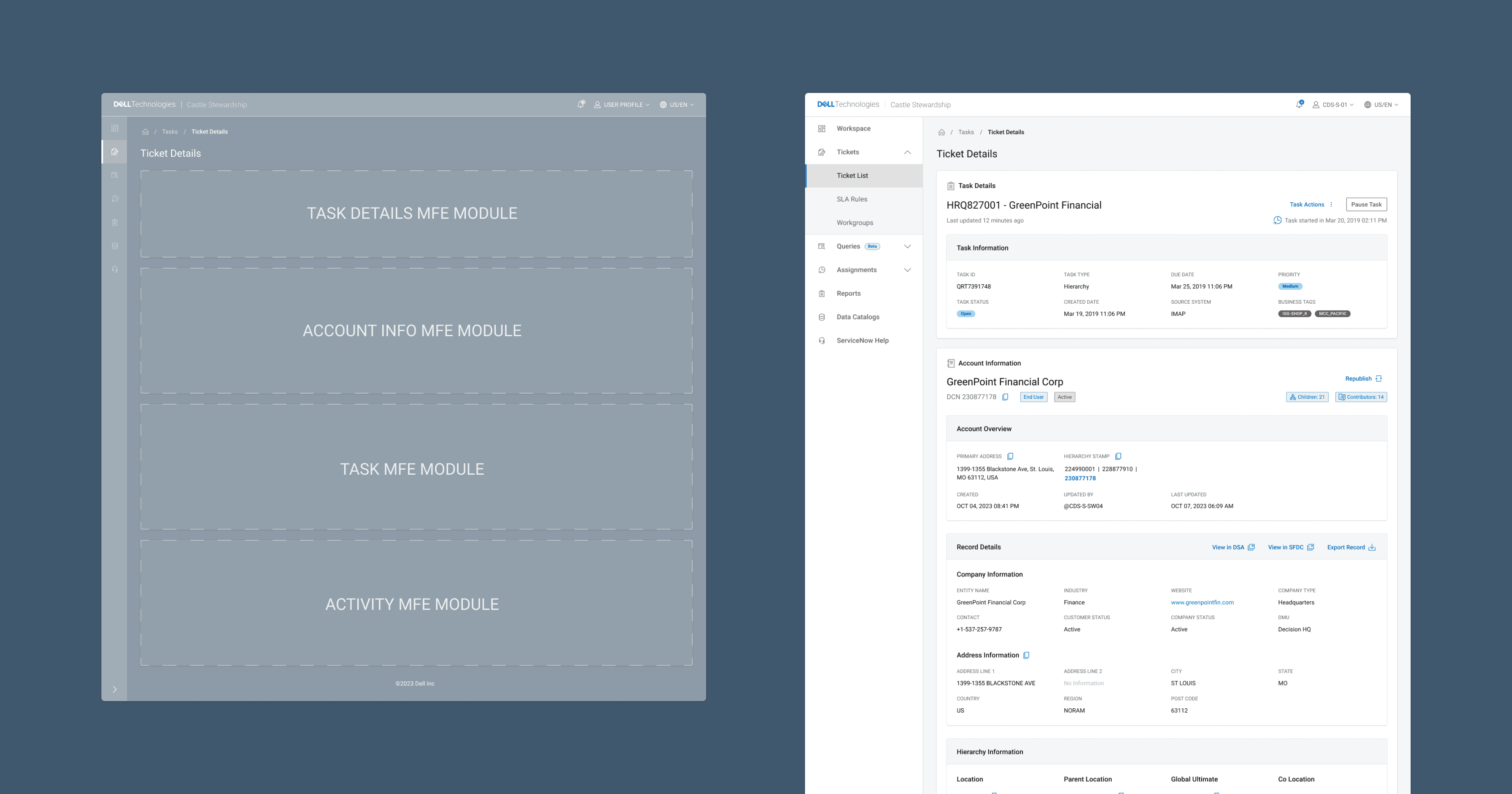
That shared skeleton meant we could standardize the ticket and customer record view experience - same interface patterns, same interaction model, while letting customer data and task-specific content live inside their own containers. The design would work for a deduplication task and an address validation task the same without requiring the steward to mentally context-switch between them, also opening opportunity to standardize how we pulled and displayed data across the tool, and possibly inside other Dell Sales application leveraging micro front-ends.
This was a win for scalability. When new task types were added post-launch, the mental model held.
PRoduction & Delivery
The product strategy we landed on was settled and ready to be pitched using a crawl to run approach: Get the essentials running first, a ticket list, the 4 initial task types, and enough infrastructure to start processing Castle DB records. Rely on established tools like DBeaver and TigerGraph for the research workflows that weren't going away. Don't over-build for year one. That was phase one.
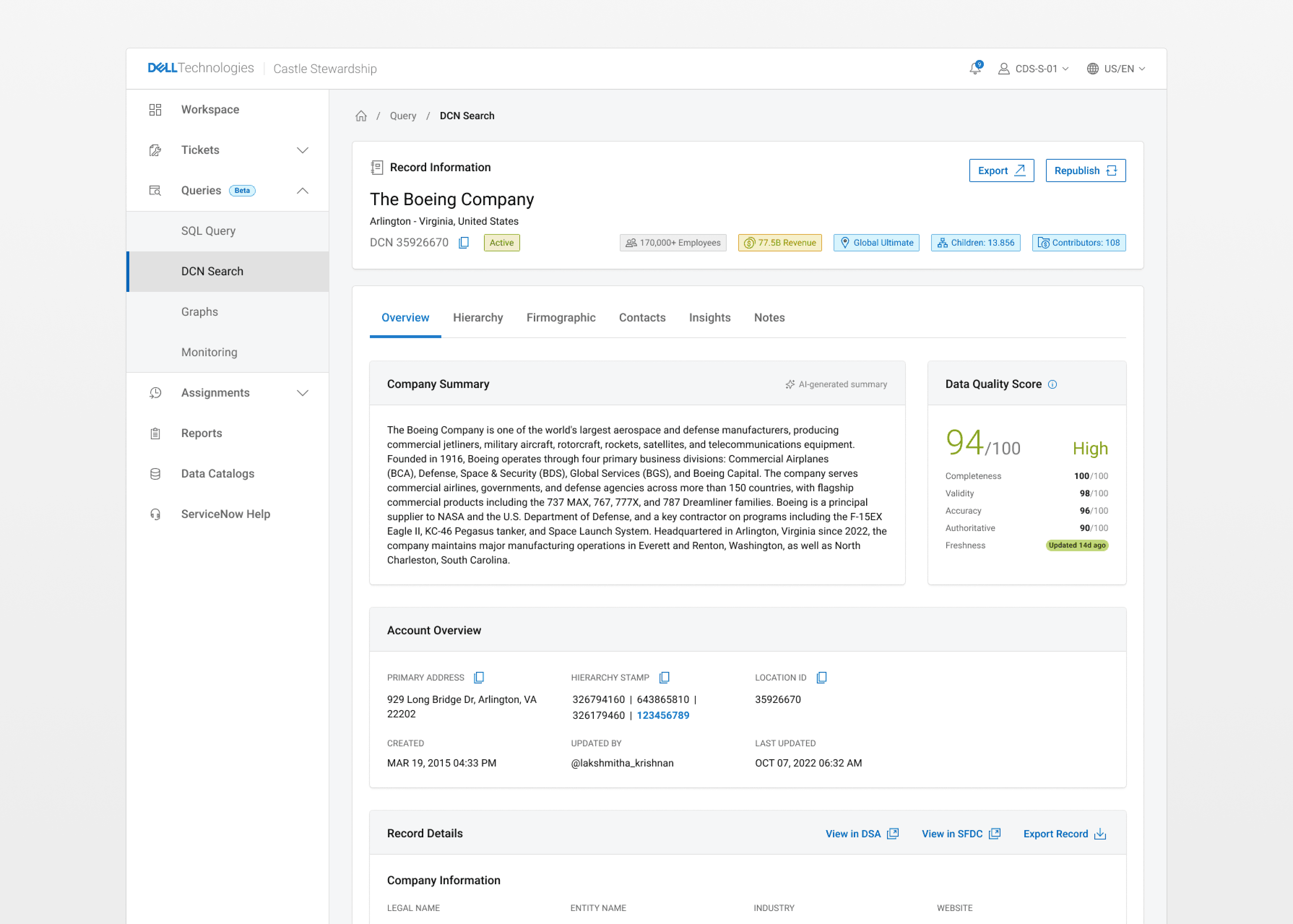
Year two target was to focus on the company's OKR as Dell's Sales AI initiatives needed reliable customer data to function. The fastest path there wasn't more features, it was cleaner data at a faster rate. We designed with that horizon in mind: a simpler, more focused stewardship tool now, with the architecture in place to layer in automation and AI capabilities as the dataset matured. That was phase two!


Impact Report
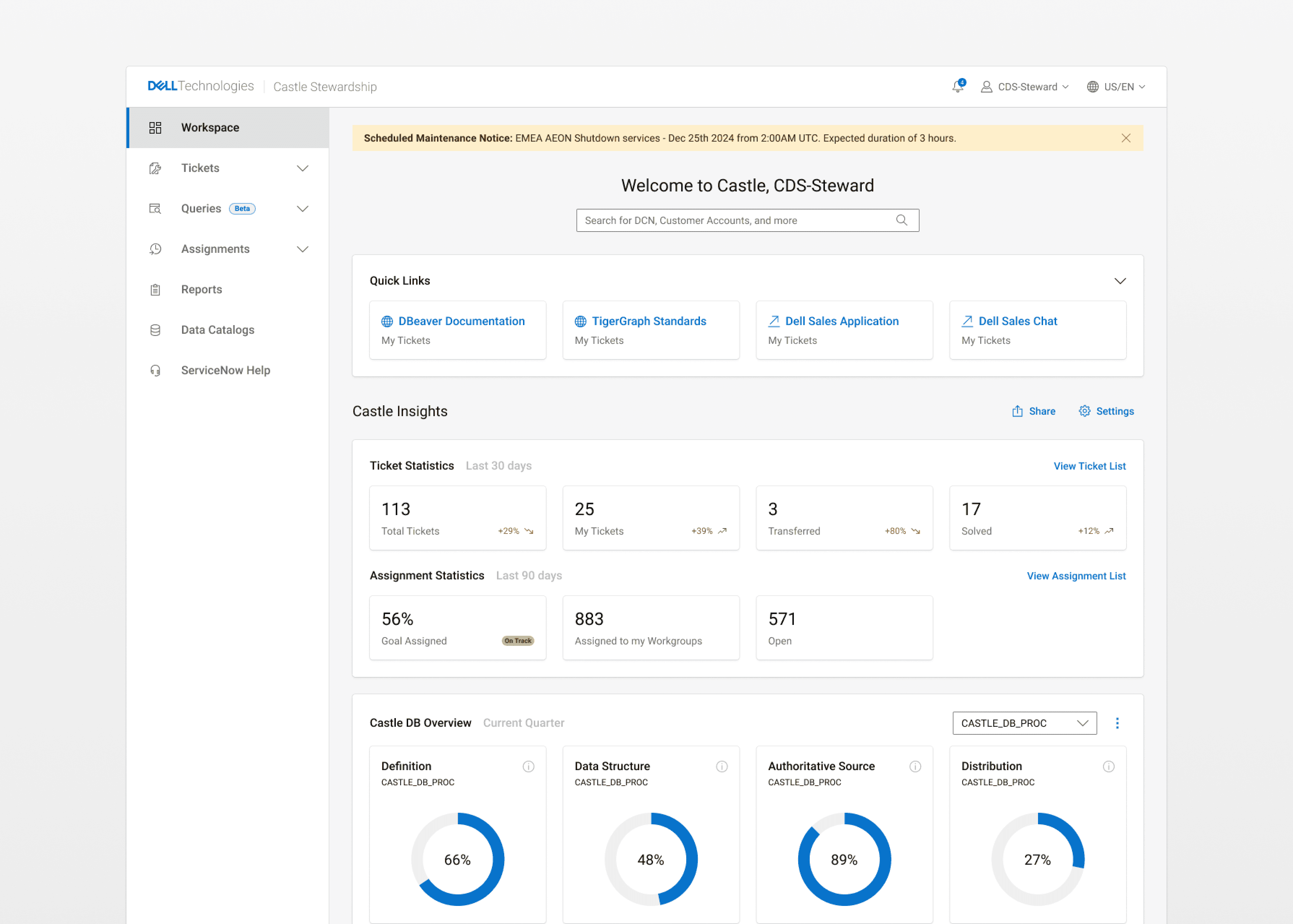
The platform shipped and iterated across FY2023–FY2025. The results were measurable in ways that mattered to the business:
After the first two quarters post-launch, the data surfaced in post launch surveys and monitored feedback showed that the primary constraint wasn't tool capability, it was steward capacity versus ticket volume. The efficiency boost was there, but the overall issues still remained, we needed a way to free up stewards time and cover more ground.
This is where I got confirmation the approach we took was correct, so we set our sights into the next challenge:
Automation rules for ticket assignment, and an AI Steward agent to handle low-complexity cases autonomously, freeing human stewards for higher-complexity work.
Debrief